News & Updates
The latest news and updates from companies in the WLTH portfolio.
Anthropic releases AI model with weaker cyber skills than Mythos
Anthropic PBC is introducing an updated version of its most powerful, widely available AI model, barely a week after it limited the release of a more advanced offering called Mythos. Anthropic said Thursday that Opus 4.7 is meant to be better at software engineering, including fielding some of the hardest coding tasks that previously required greater supervision. The company said it follows a user's instructions much better than previous models and can inspect higher-resolution images, making it possible to do things like identify details in complicated charts or pictures. However, the new model is less broadly capable than Mythos, including for cybersecurity uses, Anthropic said. During the training process for Opus 4.7, Anthropic went so far as to experiment with ways to "differentially reduce" the model's cyber capabilities, according to a company blog post. Last week, Anthropic warned that its Mythos system was able to identify and then exploit vulnerabilities "in every major operating system and every major web browser when directed by a user to do so." The company decided to only make a version of the model available to select businesses to help them safeguard their software. "We are releasing Opus 4.7 with safeguards that automatically detect and block requests that indicate prohibited or high-risk cybersecurity uses," the company said in the blog post. "What we learn from the real-world deployment of these safeguards will help us work towards our eventual goal of a broad release of Mythos-class models." The Claude maker is locked in a heated rivalry with OpenAI to deploy better artificial intelligence models and convince more business customers to pay for them. In recent months, Anthropic has seen strong momentum for its AI coding offerings as well as growing traction with consumers amid a standoff with the Pentagon over AI safeguards. Anthropic was most recently valued at $380 billion. The company is now fielding offers from investors for a new round of funding that could value it at about $800 billion or higher.

Anthropic unveils new AI model with reduced cyber capabilities
Anthropic PBC has launched an updated version of its most powerful AI model, Opus, shortly after restricting access to its advanced model, Mythos. The new model is designed to have weaker cyber skills compared to Mythos, reflecting the company's cautious approach to AI deployment. This release aims to balance innovation with safety in the rapidly evolving AI landscape.
Anthropic launches Claude Opus 4.7, migration advice
Anthropic said Claude Opus 4.7 is generally available, but the direct upgrade from Opus 4.6 may burn more tokens. Like most model releases, Anthropic outlined benchmarks and Opus 4.7 performance across multiple tasks. But Anthropic also outlined the following: "Opus 4.7 is a direct upgrade to Opus 4.6, but two changes are worth planning for because they affect token usage. First, Opus 4.7 uses an updated tokenizer that improves how the model processes text. The tradeoff is that the same input can map to more tokens -- roughly 1.0-1.35× depending on the content type. Second, Opus 4.7 thinks more at higher effort levels, particularly on later turns in agentic settings. This improves its reliability on hard problems, but it does mean it produces more output tokens." Anthropic said customers can control token usage with parameters, adjusting task budgets or prompting the model to be more concise. Anthropic did say its own testing has found the net effect on token usage if favorable. The company also published a migration guide with more advice. The migration guide that goes with Claude Opus 4.7 shows how token consumption is being more closely watched and there can be hiccups in LLM upgrades. As for the performance, Opus 4.7 performs better than Opus 4.6 on advanced software engineering, long-running tasks and verifying outputs. The model also has better vision and can see images in greater resolutions. However, Opus 4.7 is less capable than the Claude Mythos that was released under Project Glasswing.
Anthropic releases Claude Opus 4.7, narrowly retaking lead for most powerful generally available LLM
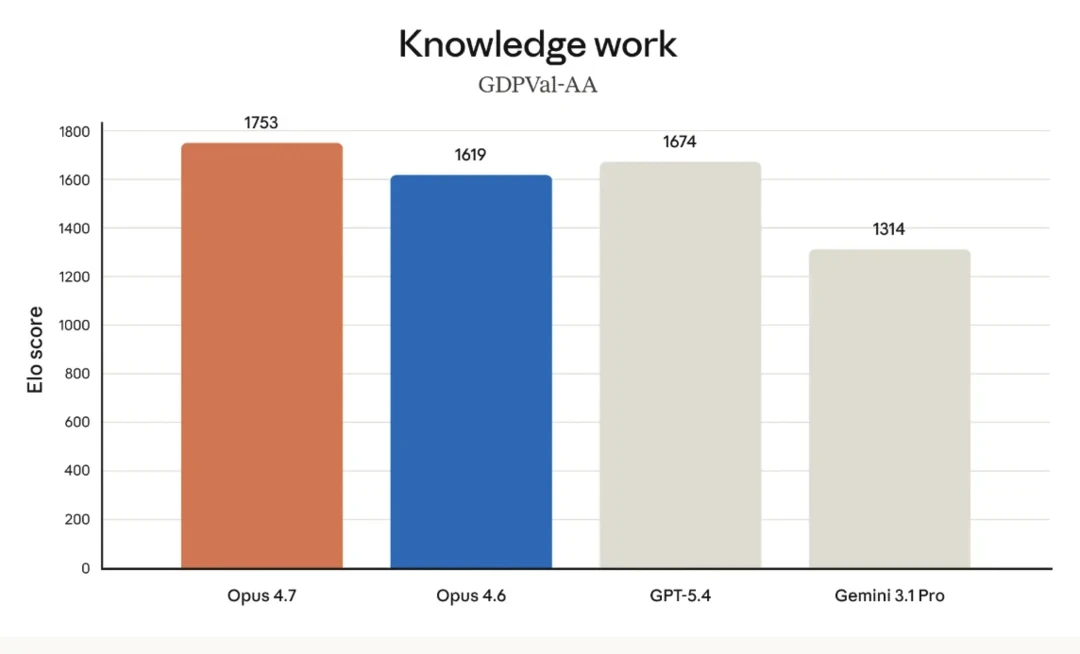
Anthropic is publicly releasing its most powerful large language model yet, Claude Opus 4.7, today -- as it continues to keep an even more powerful successor, Mythos, restricted to a small number of external enterprise partners for cybersecurity testing and patching vulnerabilities in the software said enterprises use (which Mythos exposed rapidly). The big headlines are that Opus 4.7 exceeds its most direct rivals -- OpenAI's GPT-5.4, released in early March 2026, scarcely more than a month ago; and Google's latest flagship model Gemini 3.1 Pro from February -- on key benchmarks including agentic coding, scaled tool-use, agentic computer use, and financial analysis. But also, it's notable how tight the race is getting: on directly comparable benchmarks, Opus 4.7 only leads GPT-5.4 by 7-4. It currently leads the market on the GDPVal-AA knowledge work evaluation with an Elo score of 1753, surpassing both GPT-5.4 (1674) and Gemini 3.1 Pro (1314). Yet, the model does not represent a "clean sweep" across all categories. Competitors like GPT-5.4 and Gemini 3.1 Pro still hold the lead in specific domains such as agentic search, where GPT-5.4 scores 89.3% compared to Opus 4.7's 79.3%, as well as in multilingual Q&A and raw terminal-based coding. This positioning defines Opus 4.7 not as a unilateral victor in all AI tasks, but as a specialized powerhouse optimized for the reliability and long-horizon autonomy required by the burgeoning agentic economy. Claude Opus 4.7 is available today across all major cloud platforms, including Amazon Bedrock, Google Cloud's Vertex AI, and Microsoft Foundry, with API pricing held steady at $5/$25 per million tokens. Claude Opus 4.7 is a direct evolution of the Opus 4.6 architecture, but its performance delta is most visible in the "hard" sciences of agentic workflows: software engineering and complex document reasoning. At its core, the model has been re-tuned to exhibit what Anthropic describes as "rigor". This isn't just marketing parlance; it refers to the model's new ability to devise its own verification steps before reporting a task as complete. For example, in internal tests, the model was observed building a Rust-based text-to-speech engine from scratch and then independently feeding its own generated audio through a separate speech recognizer to verify the output against a Python reference. This level of autonomous self-correction is designed to reduce the "hallucination loops" that often plague earlier iterations of agentic software. The most significant architectural upgrade is the move to high-resolution multimodal support. Opus 4.7 can now process images up to 2,576 pixels on their longest edge -- roughly 3.75 megapixels. This represents a three-fold increase in resolution compared to previous iterations. For developers building "computer-use" agents that must navigate dense, high-DPI interfaces or for analysts extracting data from intricate technical diagrams, this change effectively removes the "blurry vision" ceiling that previously limited autonomous navigation. This visual acuity is reflected in benchmarks from XBOW, where the model jumped from a 54.5% success rate in visual-acuity tests to 98.5%. On the benchmark front, Opus 4.7 has claimed the top spot in several critical categories: Crucially, Anthropic warns that this increased precision requires a shift in how users approach prompting. Opus 4.7 follows instructions literally. While older models might "read between the lines" and interpret ambiguous prompts loosely, Opus 4.7 executes the exact text provided. This means that legacy prompt libraries may require re-tuning to avoid unexpected results caused by the model's strict adherence to the letter of the request. The "agentic" nature of Opus 4.7 -- its tendency to pause, plan, and verify -- comes with a trade-off in token consumption and latency. To address this, Anthropic is introducing a new "effort" parameter. Users can now select an xhigh (extra high) effort level, positioned between high and max, allowing for more granular control over the depth of reasoning the model applies to a specific problem. Internal data shows that while max effort yields the highest scores (approaching 75% on coding tasks), the xhigh setting provides a compelling sweet spot between performance and token expenditure. To manage the costs associated with these more "thoughtful" runs, the Claude API is introducing "task budgets" in public beta. This allows developers to set a hard ceiling on token spend for autonomous agents, ensuring that a long-running debugging session doesn't result in an unexpected bill. These product changes signal a maturing market where AI is no longer a novelty but a production line item that requires fiscal and operational guardrails. Furthermore, Opus 4.7 utilizes an updated tokenizer that improves text processing efficiency, though it can increase the token count of certain inputs by 1.0-1.35x. Within the Claude Code environment, the update brings a new command. Unlike standard code reviews that look for syntax errors, is designed to simulate a senior human reviewer, flagging subtle design flaws and logic gaps. Additionally, "auto mode" -- a setting where Claude can make autonomous decisions without constant permission prompts -- has been extended to Max plan users. Anthropic continues to walk a narrow line regarding cybersecurity. The recent announcement of the aforementioend cybersecurity partnership around Mythos with external industry partners -- known as "Project Glasswing" -- highlighted the dual-use risks of high-capability models. Consequently, while the flagship Mythos Preview model remains restricted, Opus 4.7 serves as the testbed for new automated safeguards. The model includes systems designed to detect and block requests that suggest high-risk cyberattacks, such as automated vulnerability exploitation. To bridge the gap for the security industry, Anthropic is launching the Cyber Verification Program. This allows legitimate professionals -- vulnerability researchers, penetration testers, and red-teamers -- to apply for access to use Opus 4.7's capabilities for defensive purposes. This "verified user" model suggests a future where the most capable AI features are not universally available, but gated behind professional credentials and compliance frameworks. In cybersecurity vulnerability reproduction (CyberGym), Opus 4.7 maintains a 73.1% success rate, trailing Mythos Preview's 83.1% but leading GPT-5.4's 66.3%. Early testimonials from enterprise customers shared by Anthropic indicate there has been a tangible shift in model perception of Opus 4.7 from 4.6, going from "impressed by the tech" to "relying on the output". Clarence Huang, VP of Technology at Intuit, noted that the model's ability to "catch its own logical faults during the planning phase" is a game-changer for velocity. This sentiment was echoed by Replit President Michele Catasta, who stated that the model achieved higher quality at a lower cost for tasks like log analysis and bug hunting, adding, "It really feels like a better coworker". Other specific reactions included: Perhaps the most telling reaction came from Aj Orbach, CEO of a dashboard-building firm, who remarked on the model's "design taste," noting that its choices for data-rich interfaces were of a quality he would "actually ship". For enterprise leaders, Claude Opus 4.7 represents a shift from generative AI as a "creative assistant" to a "reliable operative." But importantly, it is not a "clean win" for every use case. Instead, it is a decisive upgrade for teams building autonomous agents or complex software systems. The primary value proposition is the model's new capability for self-verification and rigor; it no longer just generates an answer but creates internal tests to verify that the answer is correct before responding. This reliability makes it a superior choice for long-horizon engineering tasks where the cost of human supervision is the primary bottleneck. However, an immediate, wholesale migration from Opus 4.6 requires caution. The model's increased literalism in instruction following means that prompts engineered to be "loose" or conversational with previous versions may now produce unexpected or overly rigid results. Furthermore, enterprises must prepare for a significant increase in operational costs. Opus 4.7 uses an updated tokenizer that can increase input token counts by 1.0-1.35x, and its tendency to "think harder" at high effort levels results in higher output token consumption. For legacy applications where prompts are fragile and margins are thin, a phased rollout with significant re-tuning is recommended. This release arrives at a paradoxical moment for Anthropic. Financially, the company is an undisputed juggernaut, with venture capital firms reportedly extending investment offers at a staggering $800 billion valuation -- more than double its $380 billion Series G valuation from February 2026. This momentum is fueled by explosive growth, with the company's annual run-rate revenue skyrocketing to $30 billion in April 2026, driven largely by enterprise adoption and the success of Claude Code. Yet, this commercial success is being contested by intense regulatory and technical friction. Anthropic is currently embroiled in a high-stakes legal battle with the U.S. Department of War (DoW), which recently labeled the company a "supply chain risk" after Anthropic refused to allow its models to be used for mass surveillance or fully autonomous lethal weapons. While a San Francisco judge initially blocked the designation, a federal appeals panel recently denied Anthropic's bid to stay the blacklisting, leaving the company excluded from lucrative defense contracts during an active military conflict. Simultaneously, Anthropic is fending off a growing rebellion from its most loyal power users. Despite the company's "market leader" status, developers have flooded GitHub and X with accusations of "AI shrinkflation," claiming that the preceding Opus 4.6 model and Claude Code product have been quietly degraded. Users report that recent versions are more prone to exploration loops, memory loss, and ignored instructions, leading some to describe the newly released Claude Code desktop app as "unpolished" and unbefitting a firm with a near-trillion-dollar valuation. Opus 4.7 is Anthropic's attempt to silence these critics by proving that "deep thinking" can be paired with the rigorous execution that its enterprise clients now demand. Ultimately, Opus 4.7 is a model defined by its discipline. In a market where models are often incentivized to be "helpful" to a fault -- sometimes hallucinating answers to please the user -- Opus 4.7 marks a return to rigor. By allowing users to control effort, set budgets, and verify outputs, Anthropic is moving closer to the goal of a truly autonomous digital labor force. For the engineering teams at Replit, Notion, and beyond, the shift from "watching the AI work" to "managing the AI's results" has officially begun.

Michael Burry Thinks Anthropic is Eating the Lunch of Palantir -- Is He Right?
This post may contain links from our sponsors and affiliates, and Flywheel Publishing may receive compensation for actions taken through them. Dr. Michael Burry of The Big Short fame doesn't seem to be willing to back down as a bear in the epic tug-of-war with Palantir (NASDAQ:PLTR | PLTR Price Prediction) shareholders and the great CEO Alex Karp. Undoubtedly, Burry seemed to have been getting his way, with shares of Palantir plunging viciously into a bear market amid one of the worst software slumps in recent memory. But after a strong rally in the broader markets heading into mid-March over hope that the Iran war will end soon, it feels like the battle between the bulls and the bears (especially among the shorts and longs) is about to get tougher to call. I'll admit that bearish remarks, especially by a man as brilliant as Michael Burry, seem to have more of an impact when the overall market mood is in a bad spot. But, just like that, the S&P 500 is at a new all-time high, and suddenly, it feels good to be back, not only in stocks or tech plays, but also in the fallen software companies that were pretty much untouchable just a few weeks ago when the threat of AI shocked many, acting as some sort of wake-up call for the industry. While Anthropic has only advanced AI further since the software slump of the SaaS-pocalypse began, I do think that investors are starting to come to the conclusion that they overreacted in a moment of panic. When a "magical" piece of new tech (and yes, AI does feel magical sometimes) comes along, doing amazing things like catching bugs galore across a slew of applications, it's only natural to think about what could happen if we're just scratching the tip of the iceburg when it comes to what the tech could be capable of in just a few years or even a few months. Could it be that markets will stop overreacting to new Anthropic or OpenAI tools when a new breakthrough is released, just like it's seemingly moved on from the Iran war? Time will tell. I guess it depends on the magnitude of the breakthrough we're talking about and whether the AI disruptor is actually able to weigh on growth and margins of a targeted software firm. In any case, it's an unprecedented time, and with so much uncertainty about who loses or wins amid AI's rise, it can be hard to know how to react. That is, if any reaction is necessary! In any case, when Michael Burry says things like Anthropic could steal Palantir's lunch, it's hard to buy the dip, even if you were previously bullish on the firm and the momentum riding behind its AI Platform. Time will tell whether it's Burry, in the red corner, or Karp, in the blue corner, that will have the last laugh. Anthropic could certainly disrupt a number of software firms with a "plug-and-play" kind of model. That's the main fear. And I won't be the first to admit that the disruptive potential of managed agents is a bit unsettling. If Anthropic's agents can move fast, perhaps the barriers to entry could be lowered. Of course, let's not forget that Palantir and other firms won't be standing still as they look to level up their own agents. If Anthropic's AI is powerful enough to upend some leaders in the AI software scene, is AI still in a bubble, as Burry suggested previously? Either way, I've noted in prior pieces that Burry might be able to win on his bearish bets, even if he's wrong about AI, as a whole, being in a bubble. Palantir is a very expensive stock on nearly every metric. And when expectations call for perfection, it gets harder to keep that applause going. Where Burry sees a "wrapper," others see immense value in the ontology. Personally, I think Palantir is more than just a "wrapper," but I'm unsure how far Anthropic and other frontier model makers will go. As such, I'm staying on the sidelines, even if Palantir stock has another double up its sleeves as software makes a comeback.

Anthropic Unveils Claude Opus 4.7, Its Most Advanced Public AI Model Yet
Claude Opus 4.7 is Anthropic's most advanced public AI model yet. | Image: Anthropic Anthropic has introduced Claude Opus 4.7, the latest iteration of its flagship AI model, positioning it as its most capable generally available system so far. The release comes at a time when competition in advanced AI models is intensifying, particularly in areas like coding, reasoning, and enterprise workflows. The new model builds on the Claude Opus series, which represents Anthropic's highest-tier models designed for complex tasks, long-form reasoning, and agent-based workflows. Claude Opus 4.7 is designed to improve performance across practical use cases rather than just benchmark gains. According to Anthropic, the model delivers better results in areas such as software engineering, image understanding, and instruction-following. It is also positioned as more capable in handling creative tasks like generating presentations and structured documents, suggesting a push toward enterprise and productivity applications. This aligns with the broader direction of AI development, where models are increasingly expected to perform multi-step tasks reliably rather than just generate text. Despite the improvements, Anthropic has been unusually clear about where Opus 4.7 stands. The model does not represent the company's most advanced capabilities overall. That distinction currently belongs to Claude Mythos Preview, a more powerful system that is being tested in restricted environments due to its potential cybersecurity implications. In fact, internal evaluations suggest Mythos outperforms Opus 4.7 across key benchmarks but remains limited to select partners for safety reasons. This positions Opus 4.7 as a bridge between widely accessible AI and more tightly controlled frontier systems. Anthropic has also emphasised safety as a key part of the update. The company has incorporated additional safeguards into Opus 4.7, particularly around sensitive areas like cybersecurity. These controls are designed to prevent misuse while still allowing legitimate applications in research and development. The model is part of a broader strategy where more advanced capabilities are gradually introduced with tighter oversight, rather than released openly. Several companies, including platforms in finance, development tools, and productivity software, have already begun testing the model. This early adoption reflects the model's positioning as a tool for real-world workflows, particularly in coding, automation, and knowledge work. Anthropic is also maintaining the same pricing structure as its previous Opus model, signalling continuity rather than a shift in monetisation strategy.

Claude Opus 4.7 launched: Smarter, safer AI - but why isn't it more powerful than Anthropic's Claude Mythos explained
Claude Opus 4.7: Anthropic has introduced a new artificial intelligence model, Claude Opus 4.7, positioning it as a practical upgrade focused on real-world tasks rather than cutting-edge power. The company said the latest version improves performance in areas like software engineering, following instructions, and handling everyday work tasks, as per a report. It is now its most powerful model available to the public. However, Anthropic made it clear that Opus 4.7 is not as broadly capable as its more advanced system, Claude Mythos Preview, which is currently limited to select companies, as per a CNBC report. Unlike Mythos Preview, which is part of the company's cybersecurity-focused Project Glasswing, Opus 4.7 comes with built-in safeguards. These protections are designed to automatically detect and block requests linked to high-risk or prohibited cybersecurity uses. Anthropic said, "We are releasing Opus 4.7 with safeguards that automatically detect and block requests that indicate prohibited or high-risk cybersecurity uses," adding, "What we learn from the real-world deployment of these safeguards will help us work towards our eventual goal of a broad release of Mythos-class models," as quoted by CNBC. Since its founding in 2021, Anthropic has focused on building a reputation around responsible AI development. Its latest release reflects that approach, balancing improved capabilities with tighter controls. The launch also follows growing attention from policymakers and industry leaders, including discussions involving members of the Trump administration, tech executives, and banking leaders about the risks tied to powerful AI systems. Anthropic noted that while Mythos-class models are not yet ready for broad release, the company aims to eventually scale them responsibly. In the meantime, Opus 4.7 builds on its predecessor, Claude Opus 4.6, outperforming it across several benchmarks such as coding, reasoning, and tool use. The model is now available across Anthropic's Claude products, API, and cloud platforms including Microsoft, Google, and Amazon, at the same price as the previous version. What is Claude Opus 4.7? It is Anthropic's latest AI model designed to handle real-world tasks more effectively. How is Opus 4.7 different from Mythos Preview? Opus 4.7 is publicly available but less advanced than Mythos Preview, which is limited to select users.

Anthropic's Claude Mythos Dilemma: When Superpowered AI Gets Risky
Anthropic's Claude Mythos Preview has sparked concern in the U.S. and globally over AI safety. Debate has spread from Wall Street and Washington, D.C., to financial institutions in Europe. Anthropic is withholding it from public release, citing the model's apparent ability to autonomously exploit previously unknown cybersecurity vulnerabilities. AI is already a kind of Pandora's box. Its impact can scale at extraordinary speed because its outputs are automated, reproducible, and easily multiplied. That does not make AI the same as a nuclear weapon. But it does make it a system-level risk. Once highly capable models are widely accessible, misuse can spread fast across industries and institutions. But commercial pressure may be moving faster than governance. The erosion of safety capacity at major AI companies has drawn scrutiny. OpenAI's reported shutdown of its Mission Alignment team earlier this year and the disbanding of dedicated AI safety team in 2024 were almost like racing a horse without a bridle. When safety functions shrink as model capability grows, the technology becomes more vulnerable to malicious use. Public anxiety is only natural. Project Glasswing To reduce cybersecurity risks, Anthropic launched Project Glasswing. It is a coordinated vulnerability disclosure effort involving Amazon Web Services, Anthropic, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks. The goal is to let major infrastructure providers use the model's predictive power to find weaknesses in cloud systems and patch critical software bugs. The idea is to fix those problems before the model, or a similar adversarial system, reaches a broader and less regulated public. This marks a shift in industry priorities. The race in AI is no longer only about capability. It is also about who can secure the systems that capability may threaten. Cross-industry Impact As AI capability rises, so do the risks across industries. In finance, models with Mythos-level reasoning could help simulate or execute complex market manipulation, evade fraud detection, or automate the discovery of institutional weaknesses. In manufacturing and commerce, advanced AI could identify and exploit supply-chain bottlenecks, causing delays, disruptions, or theft at scale. In universities and research institutions, the threat extends to proprietary research data, internal networks, and AI-assisted social engineering attacks against administrators and faculty. As AI becomes a general-purpose tool for productivity, it also becomes a general-purpose tool for sabotage. The same flexibility that makes it commercially valuable also makes it highly adaptable for malicious use. Medicine and the Data Integrity Crisis The 2026 Stanford AI Index Report, released this month, highlights a sharp increase in AI adoption in medicine. It notes a significant rise in AI uses for clinical documentation, medical imaging, and diagnostic reasoning. That growth may improve efficiency. But it also expands the attack surface for public health if mis-deployed. If a model like Mythos were used to corrupt medical databases, manipulate diagnostic systems, or generate inaccurate pharmacological guidance, the damage would go far beyond an ordinary data breach. It would create a direct threat to patient safety. As healthcare systems become more dependent on AI-mediated workflows, the prospect of adversarial medicine becomes harder to dismiss. In such cases, bad actors could manipulate AI outputs to cause harm, create confusion, or extort hospitals. In that context, identity verification and access controls look less like optional friction and more like core infrastructure. Inevitable Identity Verification The possibility that high-capability models could enable such harms has accelerated a shift toward mandatory identity verification. Anthropic now requires government-issued identification and biometric live selfies from users seeking access to certain high-risk functions. The company frames this as a matter of platform integrity, arguing that responsible use of powerful technology begins with knowing who is using it. To address privacy concerns, Anthropic says the verification data is not used to train models and is not shared with third parties for marketing or advertising. Physical ID checks for AI use may feel like a major change in user experience. But they also extend a much older industry practice. For years, technology companies have relied on passive forms of verification. Google sign-ins for Gemini, internet service registrations, and the metadata tied to email accounts, devices, and digital purchases already provide dense identity signals. Those systems have long supported public-safety functions and commercial monetization. Explicit identity checks for advanced AI models formalize that trajectory. They move the industry from background identification to foregrounded, bank-grade authentication. The Missing Public Role Anthropic's Project Glasswing brings together major cloud providers and cybersecurity companies. But it does not yet appear to meaningfully include public institutions or policymakers. The gap matters. Innovation is vital to economic competitiveness. But safety remains a precondition for lasting growth. Governments once built legal frameworks for cybersecurity and data privacy. They now need to update AI safety laws and regulatory mechanisms to match the capabilities of new models. Without that public framework, too much of the burden will fall on private firms whose incentives do not always align with the public interest. The real question is whether institutions can move fast enough to govern it before the technology outruns existing controls.

Anthropic's Claude Opus 4.7 Beats GPT-5.4 in Coding Benchmark
Anthropic has launched Claude Opus 4.7, its latest flagship model that brings a notable improvement in advanced software engineering and upgraded high-resolution vision. Coming two months after the release of Claude Sonnet 4.6, the new model builds on that foundation with stronger performance on complex, long-running tasks that previously required closer supervision. The big story here is software engineering. Benchmark data shows that Opus 4.7 achieved a 64.3% score on the SWE-bench Pro test, which measures how well an AI can fix real-world GitHub issues. That is a clear jump from the 53.4% seen in the previous 4.6 version and places it ahead of OpenAI's GPT-5.4, which scored 57.7%. For developers on the Mac, the model is well-suited for use with Apple's Xcode 26.3, which introduced support for autonomous AI agents that can handle longer, multi-step workflows. The vision side of the model has also been significantly upgraded. Opus 4.7 can now process images up to 2,576 pixels on the long edge, which works out to about 3.75 megapixels. That is more than triple the resolution limit of previous Claude models. This added detail supports use cases like computer control on macOS, where an AI agent needs to read dense text from screenshots or navigate complex diagrams and user interfaces with precision. Safety and security remain a major focus following the introduction of Project Glasswing, which highlights both the risks and benefits of using AI models in cybersecurity. Opus 4.7 is the first model in this rollout to include safeguards designed to detect and block high-risk or prohibited cybersecurity requests. For legitimate security researchers, Anthropic is launching a Cyber Verification Program to allow access for vulnerability testing and red-teaming. Anthropic is also giving users more control over how the model thinks. A new "xhigh" effort level has been added between the high and max settings, letting you fine-tune the balance between reasoning depth and latency. In the Claude Code desktop environment, a new /ultrareview command can now be used to flag bugs and design flaws that a standard code review might miss. The model also introduces improvements to memory and real-world task performance. Opus 4.7 is better at using file system-based memory, allowing it to retain important context across long, multi-session workflows. Anthropic says it also delivers stronger results in finance-related evaluations and broader knowledge work benchmarks, producing more rigorous analyses and higher-quality outputs across complex tasks. There is a small catch for those migrating from Opus 4.6. This new version uses a more literal instruction-following style, which means prompts that were written to be interpreted loosely may need to be re-tuned. It also features an updated tokenizer that improves text processing but can increase token usage for some inputs by roughly 1.0 to 1.35 times, depending on the content. Claude Opus 4.7 is generally available today via the Claude API and through cloud providers like Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. Pricing remains the same as the previous version at $5 per million input tokens and $25 per million output tokens.

Musk's SpaceX Targets Public Listing Amid Starlink Expansion
SpaceX is accelerating plans for a potential public market debut, buoyed by rapid growth in its satellite internet business, Starlink, which has continued to attract millions of new users globally. According to report, Starlink has recorded significant expansion in its user base, with both app downloads and monthly active users more than doubling in the first quarter of 2026 compared to the same period last year. The report highlighted that the service has now achieved four consecutive quarters of over 100 per cent growth in monthly active users, underlining its position as the key revenue driver for SpaceX ahead of its anticipated initial public offering (IPO). While the strong growth trajectory of Starlink is central to SpaceX's valuation, with projections placing the company's worth as high as $1.75 trillion as it prepares for what could become the largest IPO in history. However, data from market intelligence firm Apptopia showed that emerging markets are playing a critical role in the expansion, with countries such as Brazil and Argentina contributing significantly to user growth. In a country like Brazil, Starlink monthly active users reportedly increased fivefold, accounting for about 13 per cent of Starlink's global user base, while Argentina recorded a 159 per cent surge in users. The United States, which remains Starlink's largest market, also witnessed strong performance, with app downloads tripling year-on-year to about 1.2 million in the first quarter of 2026. Starlink's global subscriber base has now surpassed 10 million as of February 2026, reflecting sustained demand for satellite-based internet services across both developed and emerging markets. It is noted that the continued expansion of Starlink's user base is critical to investor confidence, particularly as SpaceX explores new ventures, including orbital data centres and broader digital infrastructure services. The anticipated IPO is expected to test investor appetite for large-scale technology listings, with SpaceX positioned as a potential benchmark for future mega public offerings globally. Experts, however, cautioned that while growth metrics remain strong, sustaining the pace of expansion will be key to justifying the company's lofty valuation in public markets. Starlink, which provides broadband internet via a constellation of low-Earth orbit satellites, has become the cornerstone of SpaceX's commercial strategy, contributing a significant share of its revenue. Hence, the development comes amid intensifying competition in the satellite internet space, with global technology firms increasing investments to challenge SpaceX's dominance in the sector.

Anthropic's Claude Opus 4.7 makes a big leap in coding, while deliberately scaling back cyber capabilities
Per-token prices stay the same, but a new tokenizer maps the same text to up to 35 percent more tokens - meaning the actual cost per request can rise significantly. Anthropic's new flagship model Claude Opus 4.7 delivers major improvements in coding tasks. During training, the company deliberately tried to reduce certain cybersecurity capabilities. Anthropic has released Claude Opus 4.7, a direct upgrade to its predecessor, Opus 4.6. The company positions the model primarily as a step forward in autonomous coding. On the SWE-bench Pro coding benchmark, Opus 4.7 scores 64.3 percent, up from 53.4 percent for its predecessor and ahead of OpenAI's GPT-5.4 at 57.7 percent. Anthropic's own top model, Claude Mythos Preview, still leads by a wide margin at 77.8 percent. Anthropic says Opus 4.7 follows instructions more precisely than its predecessor. The company notes that prompts written for older models may now produce unexpected results, as Opus 4.7 interprets instructions more literally than Opus 4.6, which sometimes loosely interpreted or skipped parts of them entirely. Opus 4.7 processes images at up to 2,576 pixels on the long edge, which Anthropic says works out to roughly 3.75 megapixels, more than three times what earlier Claude models could handle. This isn't an API setting but a model-level change: images are automatically processed at higher resolution, though they consume more tokens as a result. Users who don't need the extra detail can downscale images before sending them. Anthropic sees this as a major advantage for computer-use agents that need to read dense screenshots and for extracting data from complex diagrams. On the Document Reasoning benchmark (OfficeQA Pro), the company reports 80.6 percent accuracy, up from 57.1 percent with Opus 4.6. The benchmarks also show significant gains in biomolecular reasoning and visual navigation (ScreenSpot-Pro). One of the more notable aspects of this release is how Anthropic handles the model's cybersecurity capabilities. The company says it experimentally tried to reduce certain cyber capabilities differentially during training. New safeguards are designed to automatically detect and block requests that suggest prohibited or high-risk cybersecurity use. The background here is the recently announced Project Glasswing, in which Anthropic addressed the risks and benefits of AI models for cybersecurity. The company had explained that it would restrict the release of the more capable Mythos Preview and first test new safeguards on less capable models. Opus 4.7 is the first test case for this strategy. Security researchers who want to use the model for penetration testing or red-teaming can sign up for a new Cyber Verification Program. According to the system card, Anthropic distinguishes between two types of hallucinations: factual hallucinations - wrong claims about the world, like fabricated quotes or incorrect data - and input hallucinations, where the model acts as if it has access to a tool or attachment that doesn't actually exist. For factual hallucinations, Opus 4.7 performs better than or on par with Opus 4.6 across four benchmarks but falls short of Mythos Preview. Anthropic says the gap comes mainly from Mythos Preview's higher hit rate on obscure facts, not from a higher error rate in Opus 4.7. For input hallucinations, Opus 4.7 achieves the lowest hallucination rate of all tested models when users request a tool that isn't available. When context information is missing, it comes close to Mythos Preview and sits well ahead of older models. Anthropic acknowledges, however, that the test cases for the tool set were tailored to Opus 4.6's weaknesses, which skews that model's results. When dealing with questions based on made-up facts Opus 4.7 performs on par with Opus 4.6 and below Mythos Preview. Under pressure, such as when users or system prompts push the model to contradict its own assessment, Opus 4.7 is more honest than Opus 4.6 but less firm than Mythos Preview. Overall, Anthropic describes Opus 4.7's safety profile as similar to Opus 4.6, with low rates of deception, sycophancy, and cooperation with misuse. The model is more resistant to prompt injection attacks. A known issue from earlier Claude models partially persists: refusing to help with legitimate AI safety research. According to the system card, Opus 4.7 still refuses to assist in 33 percent of simulated safety research tasks. That's a significant drop from 88 percent with Opus 4.6, but still a substantial share. Pricing stays at $5 per million input tokens and $25 per million output tokens. However, Opus 4.7 uses a new tokenizer that can map the same text to up to 1.35 times as many tokens. The model also generates more output tokens at higher effort levels. In practice, the cost per request can rise significantly even though the per-token prices remain unchanged. A new effort level called "xhigh" slots in between "high" and "max." Claude Code also gets a new "/ultrareview" command for dedicated code reviews and an expanded "Auto Mode" for Max users, where Claude makes decisions on its own. Opus 4.7 is available through the Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry.
XAI Renting GPUs to Cursor - Further GPU Rents Enables Breakeven | NextBigFuture.com
It is being reported that xAI will rent tens of thousands of GPUS to AI coding company Cursor. It is about $2.5-18 per hour for GPU rentals. For 10,000 GPUs it would be $15-40 million of rent. For 50,000 GPUs it would be $75 million to $200 million per month. If XAI was renting half of their installed GPUs to more customers then it about be about 200,000 to 300,000 GPUs. If we consider 200,000 GPUs then it would be about $280 million to $800 million per month. $800 million per month would be $10 billion per year and this would mostly offset the remaining current losses at XAI.

Anthropic releases Claude Opus 4.7, concedes it trails unreleased Mythos
Why it matters: Anthropic publicly conceded that the new Opus model does not match the performance of Mythos, a highly advanced system that the company hasn't released to the public due to safety concerns. * In a chart accompanying its announcement, Anthropic showed that Opus 4.7 beats Opus 4.6, ChatGPT 5.4, Google Gemini 3.1 Pro in a number of key benchmarks. * But Opus 4.7 still falls short of its Mythos Preview model, which has only been released to a handpicked group of tech and cybersecurity companies. What they're saying: "Opus 4.7 is a notable improvement on Opus 4.6 in advanced software engineering, with particular gains on the most difficult tasks," Anthropic said in a blog post. * "Users report being able to hand off their hardest coding work -- the kind that previously needed close supervision -- to Opus 4.7 with confidence." * "The model also has substantially better vision: it can see images in greater resolution," it said. "It's more tasteful and creative when completing professional tasks, producing higher-qualityinterfaces, slides, and docs." The big picture: The release arrives amid weeks of user complaints that Opus 4.6 had quietly gotten worse. * "Claude has regressed to the point it cannot be trusted to perform complex engineering," an AMD senior director wrote in a widely shared post on GitHub. * Speculation centered on whether Claude has been deliberately scaled back -- what users are calling "nerfed" -- either to control costs or to redirect scarce compute toward Mythos and other frontier efforts. * Anthropic denied that any changes it made were to redirect computing resources to other projects. Zoom in: In addition to the new model, Anthropic is shifting its default level of reasoning in Claude Code and offering a new option. * "Opus 4.7 introduces a new xhigh ("extra high") effort level between high and max, giving users finer control over the tradeoff between reasoning and latency on hard problems," Anthropic said."When testing Opus 4.7 for coding and agentic use cases, we recommend starting with high or xhigh effort." * It's also testing a new system called "task budgets" that give developers more control over how Claude does its reasoning on longer tasks. Between the lines: Anthropic said it will use the new release to test guardrails designed to prevent its model being used for cybersecurity attacks.

Anthropic releases Claude Opus 4.7, resolving April 16 market YES
Anthropic released Claude Opus 4.7 on April 16. The market for Claude 4.7 being released by April 16 now sits at YES, up from 26% just 24 hours ago. Trading volume hit $98,787 in actual USDC for the April 16 market. It took just $44 to move the odds by 5 percentage points, which means the market was active but not particularly deep. The largest single movement was a 24-point drop at 3:31 PM as prices rapidly adjusted to the confirmed news. ## What to watch The market's attention now shifts to the next potential catalyst: the release of Claude 5. There's no direct information from this event about Claude 5's timing, but traders will be watching for signals from Anthropic, particularly from CEO Dario Amodei or President Daniela Amodei. Follow @AnthropicAI for announcements, and watch for updates in their official blog posts or through tech insiders like Rowan Cheung. ## API access

Tomodachi Life: Living the Dream devs say the Mii programming was 'pure chaos and 'really hard to manage' during development, that it took 'six or seven years' to fine-tune
The dev team "came up with more and more ideas as development progressed" * The Tomodachi Life: Living the Dream dev team spent "six or seven years" programming the Mii interaction system * Lead programmer Takaomi Ueno says it was "pure chaos" * The team kept coming up with additional ideas throughout the years before it was finally complete Tomodachi Life: Living the Dream lead programmer Takaomi Ueno has said one of the most challenging aspects of development was Mii interactions and that it took around "six or seven years" to get right. In a new Nintendo Ask the Developer interview with the Living the Dream creators, Ueno explained that designing the way Mii characters interact with the game's features was "no easy feat for the programmers," and it took years to fine-tune. This included features in the user-generated content (UGC) system, things players can create themselves, item interactions, dialogue, and more. "Mii characters would sometimes pace up and down the same area, or several of them would try to use the same item at once... So, we set rules for each of those unintended behaviors, keeping the ones we thought were odd but amusing," Ueno said. "After layering all those elements so they wouldn't fall apart no matter how they were combined, everything finally clicked into place and made sense. Before we had those rules in place, it was pure chaos and really hard to manage." The lead programmer even admitted that there was a point where the team "thought leaving it chaotic like that might actually be kind of fun (laughs)." Art director Daisuke Kageyama added that the team kept experimenting "back when it was pure chaos" without actually finding the "right solution" because it kept asking what players would enjoy seeing. "It feels like we spent the entire project fine-tuning that balance," said game director Ryutaro Takahashi. "(Laughs) It took a long time until the final vision was clear, and we could say, 'Now we just have to build the thing!' We originally planned to finish the UGC tools in about a year and a half. But because we wanted players to enjoy the game simply by observing the Mii characters, we came up with more and more ideas as development progressed." Programming director Naonori Ohnishi added, "Takahashi-san and the UGC planner kept coming up with ideas like, 'We want this feature...oh, and this one too'," before Takahashi revealed that the team "ended up spending six or seven years on it (laughs)." The director explained that the team conducted playtests after the system was finally at a point they were happy with, and the feedback was "overwhelmingly positive, which was a big relief." "Since we'd struggled with it for so long, it was really reassuring to hear that people had found it fun," Kageyama added. Tomodachi Life: Living the Dream is now available to play on Nintendo Switch and Nintendo Switch 2. Follow TechRadar on Google News and add us as a preferred source to get our expert news, reviews, and opinion in your feeds. Make sure to click the Follow button! And of course you can also follow TechRadar on TikTok for news, reviews, unboxings in video form, and get regular updates from us on WhatsApp too.

Anthropic plans Project Glasswing expansion in UK, may offer Claude Mythos early access to ...
After offering a look at Mythos to a select group of US banks like JP Morgan, and tech giants including Google, Microsoft and Apple, Anthropic is now set to grant a select group of financial institutions in the UK early access to its AI model as early as next week, a report has said. The move marks an expansion of Project Glasswing, an exclusive program designed to test the model's ability to detect, potentially exploit, and fix critical cybersecurity flaws.According to a report by Bloomberg, the rollout comes after internal testing revealed Mythos is a powerhouse for uncovering "zero-day" vulnerabilities, which are security holes previously unknown to software developers. According to Anthropic, the AI has already identified thousands of such flaws across every major operating system and web browser."We are putting our own safeguards and our own limitations around this product because we know how powerful it can be," said Pip White, Anthropic's head for the UK, Ireland and Northern Europe, in a recent Bloomberg Television interview.The power of Mythos has sent ripples through the highest levels of finance and government. While the program initially included tech giants like Apple, Microsoft, Google and Amazon, its expansion into the banking sector has sparked a sense of urgency among regulators.In the US, Treasury Secretary Scott Bessent and Fed Chair Jerome Powell recently held emergency talks with Wall Street leaders regarding the model. On the other side in the UK, Bank of England Governor Andrew Bailey warned that global regulators must move quickly to evaluate the potential threats posed by such advanced AI.The UK's AI Security Institute confirmed to the publication that it has already tested the model, describing it as a "step up" from previous technology, particularly in its ability to simulate complex, multi-stage cyberattacks.Meanwhile, Anthropic is doubling down on its commitment to the UK. White confirmed that the company plans to open a new London office in the first quarter of next year. The company is expanding its presence in London with new office space for 800 people. The maker of the Claude AI chatbot currently has more than 200 people based in London, the company said in a statement."London is already one of our most important research and commercial hubs outside the US, and our expansion in the Knowledge Quarter gives us the room to grow into. The UK combines ambitious enterprises and institutions that understand what's at stake with AI safety with an exceptional pool of AI talent -- we want to be where all of that comes together," Pip White, Anthropic's head of EMEA north, said in a statement.

SpaceX and Other Elon Musk Companies Are Propping Up Cybertruck Sales
Elon Musk’s companies appear to be keeping Cybertruck sales afloat, as consumer demand for the electric pickup truck has taken a nosedive. Citing data from S&P Global Mobility, Bloomberg reports that Musk-linked companies have made up a significant share of recent Cybertruck registrations. SpaceX, xAI, Neuralink, and The Boring Company together accounted for nearly one in five Cybertrucks registered in the U.S. during the three months ending in December. SpaceX alone was responsible for 1,279 registrations, over 18% of the 7,071 Cybertrucks registered in that period. Musk’s other companies accounted for 60 additional vehicles. It’s unclear how much those companies paid for the trucks, but with the Cybertruck starting at $69,990, the purchases likely exceed $100 million. Bloomberg reports that the purchases have continued into this year. Tesla did not immediately respond to a request for comment from Gizmodo. The report comes as Cybertruck sales have dropped significantly in 2025, falling 48% to 20,237 units, according to Cox Automotive. Tesla first began delivering the long-awaited pickup in 2023, with Musk later predicting it could reach as many as s 250,000 units annually by 2025. He was way off. But it’s not just the Cybertruck seeing a drop in demand. Tesla’s overall deliveries also fell 9% to 1,636,129 vehicles last year. Meanwhile, BYD overtook Tesla as the world’s largest EV seller in 2024, delivering 2.26 million EVs in 2025, up 28% from 2024. Some of the slowdown could be tied to broader industry trends. Demand for EVs in the U.S. has fallen off in part due to the expiration of federal EV subsidies, prompting several car makers to rethink their EV strategies in the country Still, Tesla has its own unique issues to contend with. Several studies have linked Musk’s political involvement to declining consumer interest in Tesla. In 2024, Musk endorsed and contributed millions to Donald Trump’s presidential campaign and later went on to lead the controversial Department of Government Efficiency (DOGE). An October study from Yale University and the National Bureau of Economic Research estimates Musk’s political activism cost Tesla at least 1 million vehicle sales between October 2022 and April 2025. Another study published in Nature in July found Musk’s politics alienated liberal consumers and even impacted their interest in buying Tesla and EVs in general. Conversely, Musk’s support for Trump did not translate into a surge of interest in EVs among conservative voters. Tesla’s solution, at least for now, appears to be leaning on Musk’s other companies. Electrek reported in December, citing unnamed sources, that SpaceX could end up buying as many as 2,000 Cybertrucks. In October, the truck’s lead engineer also posted on X that SpaceX was replacing its gas-powered support vehicle fleet with Cybertrucks, sharing a photo of the vehicles at the company’s Starbase facility.

Anthropic Unveils Claude Opus 4.7 with New Adaptive Thinking for Developers
Anthropic has released Claude Opus 4.7, positioning it as the company's strongest generally available model for coding, enterprise workflows, and autonomous agent tasks. The April 2026 update brings significant architectural changes that developers will need to understand before migrating from previous versions. The headline feature is adaptive thinking -- a departure from the fixed thinking budgets in earlier releases. Rather than allocating a set compute budget for every query, Opus 4.7 now decides dynamically when to invest reasoning tokens. Simple lookups get quick responses. Complex debugging gets deeper analysis. Anthropic claims this reduces overthinking, a problem that plagued version 4.6. Claude Code users will notice an immediate shift: the default effort level is now "xhigh," a new tier sitting between "high" and "max." Anthropic recommends this setting for most coding work, particularly API design, legacy code migration, and large codebase reviews. The effort hierarchy now breaks down like this: Existing Claude Code users who haven't manually configured effort levels will be automatically upgraded to xhigh. Here's what matters for teams watching their API bills: Opus 4.7 uses an updated tokenizer and tends to think more heavily on later turns in extended sessions. This improves coherence over long conversations but can spike token usage if you're not careful. Anthropic's guidance is blunt -- treat Claude less like a pair programmer you're guiding line-by-line and more like a senior engineer you're delegating to. Front-load your specifications. Batch your questions. Reduce back-and-forth. The company also notes that Opus 4.7 calls tools less frequently and spawns fewer subagents by default. If your workflows depend on aggressive file searching or parallel task execution, you'll need to explicitly prompt for that behavior. Response length calibration has changed. Opus 4.7 won't pad simple answers with unnecessary verbosity -- a common complaint about 4.6. If you need specific output formats, state them explicitly. For teams running production workloads, the "auto mode" feature (now in research preview for Claude Code Max users) allows the model to execute without frequent check-ins. Toggle it with Shift+Tab when you trust the model to run autonomously. Extended thinking with fixed budgets is gone entirely. If you want more reasoning, prompt for it: "Think carefully and step-by-step." Want speed over depth? Tell it to "prioritize responding quickly." The bottom line for development teams evaluating the upgrade: don't port over old settings blindly. Experiment with effort levels during the same task to find your optimal cost-performance balance.

OpenAI focuses on business users amid competition with rival Anthropic
The same ChatGPT chatbot that gave OpenAI's chief financial officer Sarah Friar a tilapia recipe for a recent Sunday night dinner at home is also now doing her most mundane tasks at work like summarizing her emails and Slack messages. Friar and other company executives are banking OpenAI's future on more of the latter as it shifts its focus to business-oriented products while shedding some of its consumer offerings as a pathway to profitability. OpenAI says it will introduce a new artificial intelligence model for "high-value professional work" as the company faces heightened competition with rival Anthropic in attracting corporate customers to adopt AI assistants in their workplaces. "You'll see a new model coming from us in short order. We feel very excited about it," Friar said in an interview with The Associated Press. OpenAI boasts of more than 900 million weekly users of its core ChatGPT product, and Friar said about 95% of them "don't pay anything" for the popular chatbot. But while all those interactions build habits and reliance, they also strain the costly computing resources needed to power the company's AI systems and highlight the need for big business customers to help pay the bills. OpenAI, valued at $852 billion, and Anthropic, valued at $380 billion, both lose more money than they make, putting the privately-owned San Francisco-based AI research laboratories in a fierce competition to generate more revenue as they race toward becoming publicly traded on Wall Street. A push to improve performance and sales of OpenAI's business-oriented products -- already Anthropic's bread and butter -- has driven OpenAI to abandon some consumer initiatives, like the AI video generator app Sora. "I think it was a little heartbreaking, but we're like, OK, it's not the main event right now," Friar said. "We need to make sure that our new model that's coming has enough compute." Codenamed Spud, OpenAI says its "smartest model yet" offers "stronger reasoning, better understanding of intent and dependencies, better follow-through and more reliable output in production." It will be part of OpenAI's answer to Anthropic's new Claude Mythos, which Anthropic claims is so "strikingly capable" that it is limiting its use to select customers because of its apparent ability to surpass human cybersecurity experts in finding or exploiting computer vulnerabilities. While most people can't use Mythos, Anthropic also on Thursday released Opus 4.7, describing it as its most powerful "generally available" model. Friar, the former CEO of neighborhood social platform Nextdoor, said business customers accounted for about 20% of OpenAI's revenue when she was hired in 2024 as chief financial officer. She said it's now 40% and expected to account for half of OpenAI's sales by the end of the year. It's a sharp turnaround from late last year, when OpenAI co-founder and CEO Sam Altman was promoting a now-shuttered Sora partnership with Disney, launching a plan to sell ads on ChatGPT and floating the idea of letting ChatGPT engage in erotica with paid adult users. Altman said on the "Mostly Human" podcast earlier this month that a sharper focus was needed -- and Friar agrees. "Tech companies, when they're growing, it's just this natural thing that happens. There's so many cool things you could do," she said, adding that companies can end up doing "really badly" if they do too many things, while "great companies are very good at, in a reasonable period of time, kind of doing that winnowing down and refocusing and it's super painful." Signaling that shift was the hiring three months ago of Slack CEO Denise Dresser to be OpenAI's first chief revenue officer. Dresser said in a recent AP interview that she has been laser-focused on meeting with corporate leaders and positioning OpenAI as the go-to platform for workplaces employing AI agents to automate a variety of computer-based job tasks. "It's really clear to me that companies are past the experimentation phase and they're into using AI to do real work," Dresser said. "Leaders at companies are recognizing that AI is probably the most consequential shift of their lifetime." But those leaders also have a choice, namely Anthropic's Claude that has become widely used by software professionals. Founded in 2021 by a group of ex-OpenAI leaders who said they wanted to prioritize AI safety, Anthropic has positioned itself as the more responsible AI vendor. The distinction drew attention when President Donald Trump's administration punished the startup after a contract dispute over AI use in the military, and Altman used the opportunity to cement OpenAI's own deal with the Pentagon. Consumer interest in Anthropic surged and the company said its annualized revenues hit $30 billion, a higher number than what OpenAI has reported, though they measure it differently. Friar and Dresser declined to reveal OpenAI's latest sales but both have suggested that Anthropic's number is inflated because it doesn't account for revenue it must share with cloud computing providers Amazon and Google. Even so, it remains a tight competition that's also tied to the health of the stock market and the future of the economy. "They're likely quite close," said Luke Emberson, a researcher at nonprofit institute Epoch AI. "Certainly the trends show Anthropic is growing much faster than OpenAI. If that continues, they're likely to cross soon." The urgency led Dresser to send a memo to OpenAI employees on Sunday, first reported by The Verge, that asserted that Anthropic's coding focus "gave them an early wedge" but expressing confidence that OpenAI has the "real structural advantage" as AI usage expands beyond software developers and OpenAI builds enough computing capacity to operate its AI systems. "Their story is built on fear, restriction, and the idea that a small group of elites should control AI," Dresser's memo said of Anthropic. "Our positive message will win over time: build powerful systems, put in the right safeguards, expand access, and help people do more." But for skeptics of the financial viability of the AI industry, the trajectory of both money-losing companies is alarming as smaller startups increasingly become dependent on their AI tools. Anthropic has imposed rate limits on heavy users, forcing some to wait for hours to use Claude, and both companies have set up service tiers that reward premium payers, said author and AI critic Ed Zitron. "It's what I call the subprime AI crisis," Zitron said. "People built their lives and they built their businesses on top of these companies that, as they try and save money, will start turning the screws." One thing that both AI leaders and critics agree on is that it is an expensive technology, though whether it is worth the cost in electricity-hungry AI computers remains to be seen. "People will say, well, 'Once they go public, they're safe.' That's not true," Zitron said. "Public companies can and will die, especially ones that are dependent on $100 billion to $200 billion every year or so, just to keep breathing." A free press is a cornerstone of a healthy democracy. Support trusted journalism and civil dialogue. Donate now

ChatGPT maker OpenAI shifts its focus to business users amid Anthropic pressure
The same ChatGPT chatbot that gave OpenAI's chief financial officer Sarah Friar a tilapia recipe for a recent Sunday night dinner at home is also now doing her most mundane tasks at work like summarizing her emails and Slack messages. Friar and other company executives are banking OpenAI's future on more of the latter as it shifts its focus to business-oriented products while shedding some of its consumer offerings as a pathway to profitability. OpenAI says it will introduce a new artificial intelligence model for "high-value professional work" as the company faces heightened competition with rival Anthropic in attracting corporate customers to adopt AI assistants in their workplaces. "You'll see a new model coming from us in short order. We feel very excited about it," Friar said in an interview with The Associated Press.
